Background
The aim of this work is to develop automatic instruments for
language learning. We attempt to develop a mispronunciation detection system to
effectively highlight pronunciation errors produced by Cantonese (L1) learners
of American English (L2).
The target learners are adults who are
native Cantonese and have learned English for some years. It is observed that
mispronunciations made in L2 are mainly due to the disparities at the phonetic
and phonotactic levels across the language pairs. Since some English phonemes
are missing from the Cantonese inventory, the Cantonese learners with accent
often substitute for an English phoneme with a Cantonese one with a
similar place or manner of articulation.
Such substitutions may lead to misunderstanding and confusion among the English
words. Fig. 1 shows the comparison between English and Cantonese phonemes.
|
|
|
|
(a)
A comparison between English
and Cantonese consonants with exemplary words. Consonants highlighted in
red are English consonants which do not exist in Cantonese. These are
predicted to be substituted by learners with Cantonese consonants
similar in place of articulation and/or manner of articulation. |
(b)
A comparison between English
and Cantonese vowels with exemplary words. Vowels highlighted in red are
not found in Cantonese and are predicted to be substituted by
phonetically-similar Cantonese vowels |
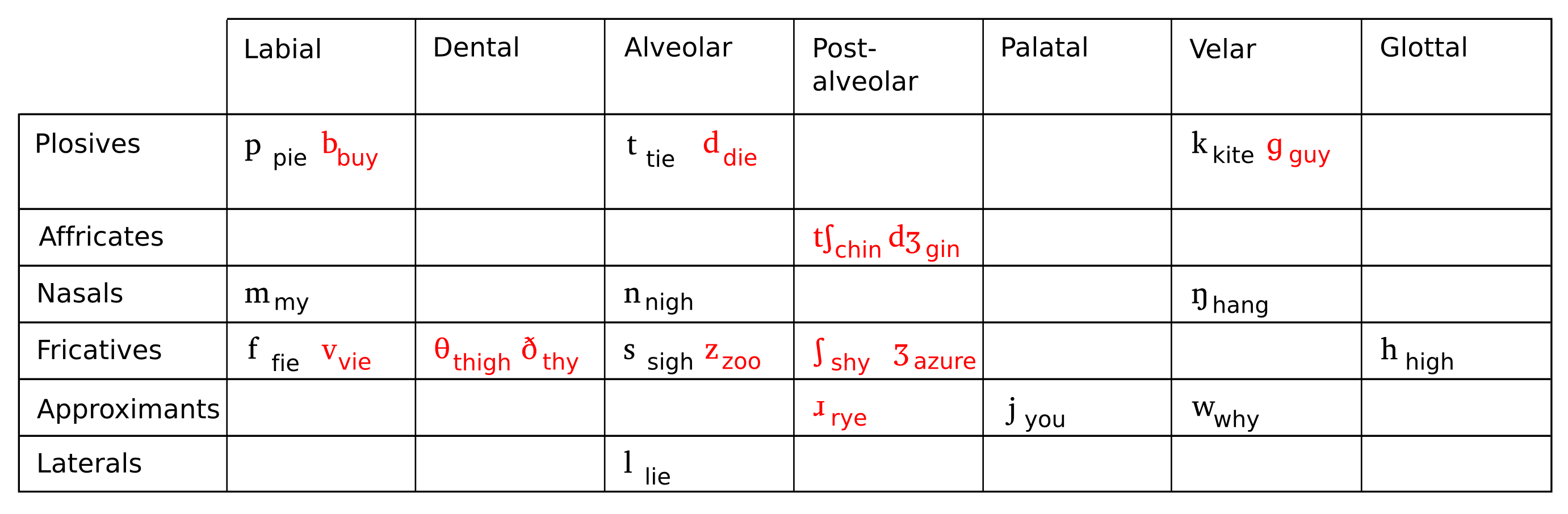
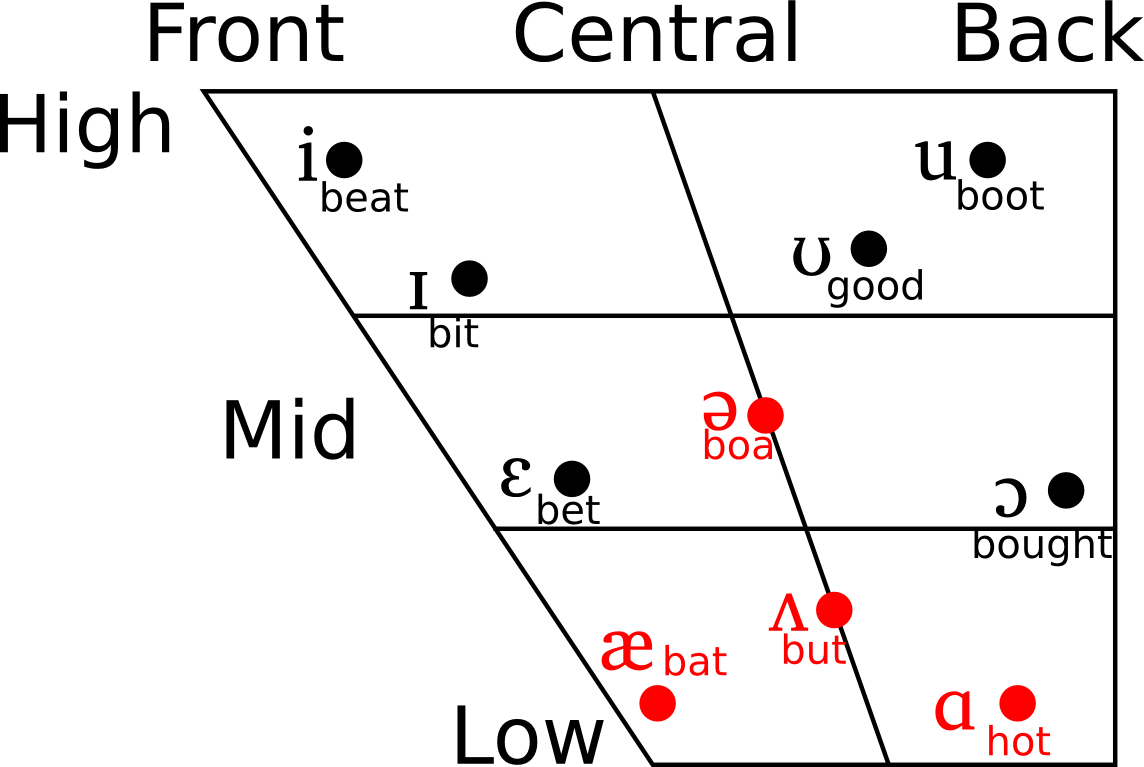
Fig. 1 The
comparison between English and Cantonese phonemes.
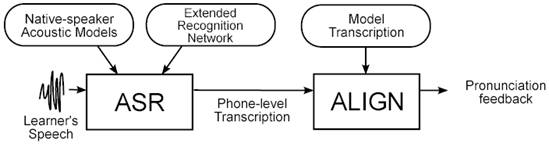
Fig. 2
Overview of ASR-based system to detect and diagnose second language learners’
mispronunciations
For further details, please refer to our publications.