Abstract: Expressive text-to-speech (E-TTS) synthesis is important for enhancing user
experience in communication with machines using the speech modality. However, one of the challenges in
E-TTS is the lack of a precise description of emotions. Previous categorical specifications may be
insufficient for describing complex emotions. The dimensional specifications face the difficulty of
ambiguity in annotation. This work advocates a new approach of describing emotive speech acoustics using
spoken exemplars. We investigate methods to extract emotion descriptions from the input exemplar of emotive
speech. The measures are combined to form two descriptors, based on capsule network (CapNet) and residual
error network (RENet). The first is designed to consider the spatial information in the input exemplary
spectrogram, and the latter is to capture the contrastive information between emotive acoustic expressions
Two different approaches are applied for conversion from the variable-length feature sequence to fixed-size
description vector: (1) dynamic routing groups similar capsules to the output description; and (2)
recurrent neural network's hidden states store the temporal information for the description. The two
descriptors are integrated to a state-of-the-art sequence-to-sequence architecture to obtain an end-to-end
architecture that is optimized as a whole towards the same goal of generating correct emotive speech.
Experimental results on a public audiobook dataset demonstrate that the two exemplar-based approaches
achieve significant performance improvement over the baseline system in both emotion similarity and speech
quality.
System Comparison
"Utterance Exemplar": The spoken utterance based on which the embedding is
obtained. The EA-TTS is expected to generate speech mimicing the emotion(s) in the given
exemplar.
"Tacotron": Baseline Tacotron system trained with style-mixed data, without
exemplar embeddings.
"GST-Tacotron": Baseline GST-Tacotron system that incorporates the global
style tokens and the Tacotron system.
"EC-TTS": E-TTS system using categorical codes recognized from the utterance
exemplar by the CapNet-based speech emotion recognizer (SER).
"EL-TTS": E-TTS system using the raw logit values generated by the SER based
on utterance exemplar.
"EP-TTS": E-TTS system using probabilistic values generated by the SER based
on utterance exemplar.
"EAli-TTS": E-TTS system using automatic residual error embedding (REE) from
the RENet with the alignment obtained from the utterance exemplar in the generation of redidual
error.
"EA-TTS": E-TTS system using automatic REE with teacher forcing generation of
redidual error.
Exemplar
Input Text
A few hours later, three weddings had taken place.
A few hours later, three weddings had taken place.
A few hours later, three weddings had taken place.
Stay there for all I care.
Stay there for all I care.
She yelled at Hermia.
Ask her to bring these things with her from the store.
I want her to marry this man, Demetrius.
Tacotron
GST-Tacotron
EC-TTS
EL-TTS
EP-TTS
EAli-TTS
EA-TTS
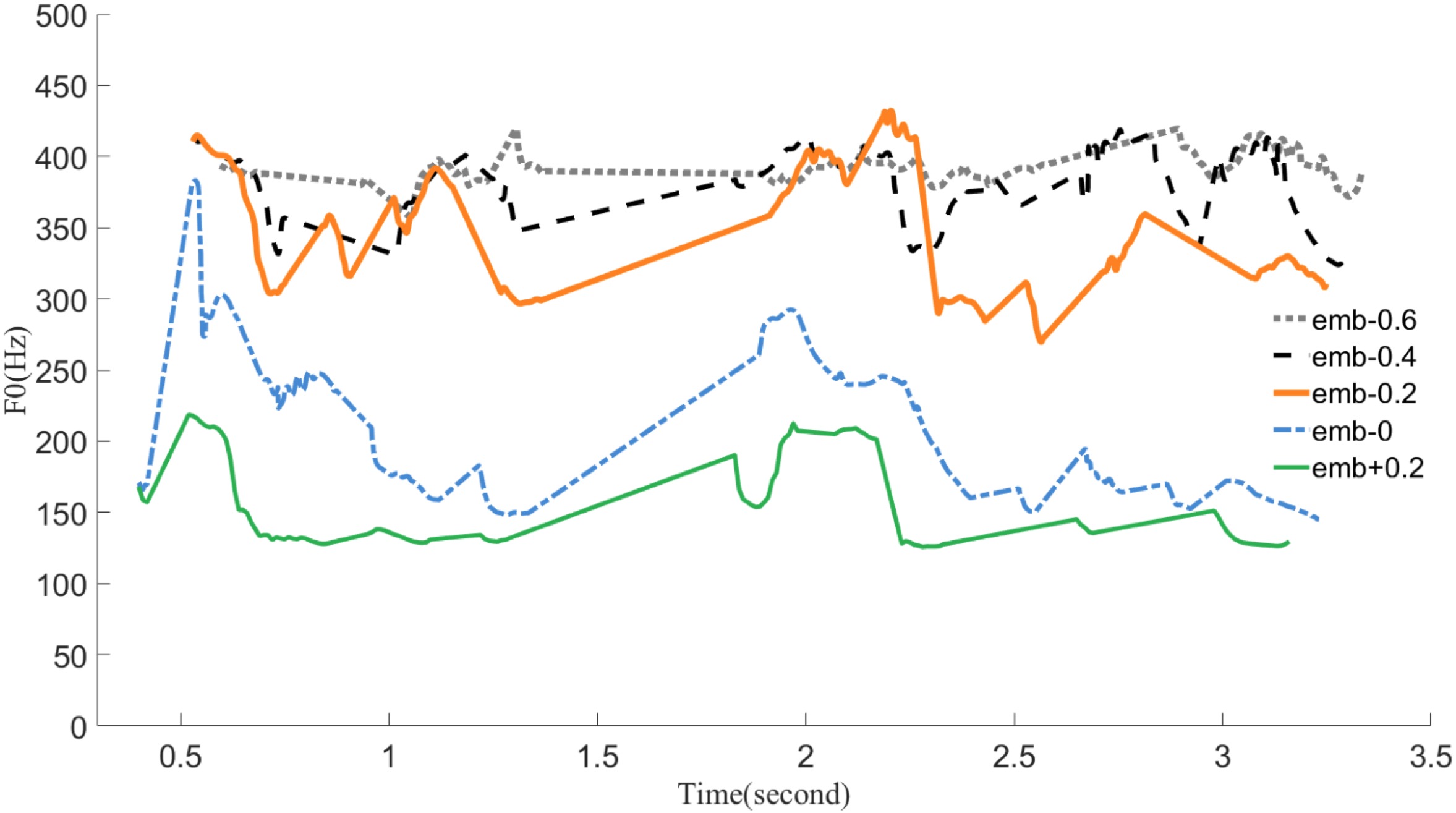
Controllability Analysis
We found that the 23-rd dimension of the residual error embedding is highly negatively
correlated to the mean F0 value of training samples. Hence we manipulate the value in that dimension while
keep the other value unchanged and generate speech based on the manipulated embedding vector. The samples
can be found as follows:
"emb-0": embedding vector extracted from an utterance exemplar.
"emb+0.2": add +0.2 to the 23-rd dimension of the
emb-0.
"emb-0.2": add -0.2 to the 23-rd dimension of the
emb-0.
"emb-0.4": add -0.4 to the 23-rd dimension of the
emb-0.
"emb-0.6": add -0.6 to the 23-rd dimension of the
emb-0.
"A few hours later, three weddings had taken place."