

Next:4.2
Optimal control of dynamicUp:4.
Optimal Control with thePrevious:4.
Optimal Control with the
4.1 Optimal control of single or parallel machine systems
We consider an n-product manufacturing system given in Section
2.1.
For any 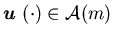 ,
define
,
define
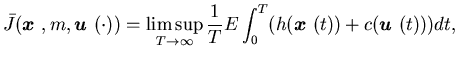
|
|
|
(4.1) |
where 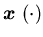 is the surplus process corresponding to the production process
is the surplus process corresponding to the production process 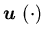 with
with 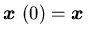 ,
and
,
and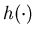 and
and 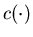 are given in Section 2.1. Our goal is to choose
so as to minimize the cost function
are given in Section 2.1. Our goal is to choose
so as to minimize the cost function 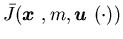 .
.
Except Assumption 2.1 in Section 2.1
on the production cost functions,
we assume the production capacity process 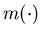 and the surplus cost function
to satisfy the following:
and the surplus cost function
to satisfy the following:
Assumption 4.1
is a nonnegative convex function with
h(0)=0. There are positive
constants C41, C42, and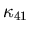 such that
such that
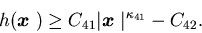
Moreover, there are constants C43 and 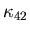 such that
such that
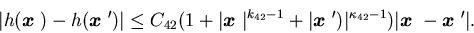
Assumption 4.2 m(t)
is a finite state Markov chain with generator Q, where Q=(qij), 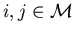 is a (p+1) x (p+1)
matrix such that
is a (p+1) x (p+1)
matrix such that  for
for 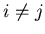 and
and 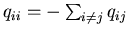 .
We assume that Q is weakly irreducible. Let
.
We assume that Q is weakly irreducible. Let 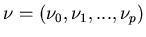 be the equilibrium distribution vector of m(t).
be the equilibrium distribution vector of m(t).
Assumption 4.3 The average
capacity 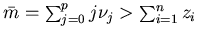 .A
control
is called stable if the condition
.A
control
is called stable if the condition
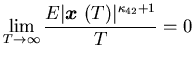 |
(4.2) |
holds, where
is the surplus process corresponding to the control
with 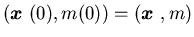 and
is defined in Assumption 4.1. Let
and
is defined in Assumption 4.1. Let 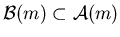 denote the class of stable controls.
denote the class of stable controls.
We will show that there exists a constant 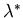 ,
independent of the initial condition ,
and a stable Markov control policy
,
independent of the initial condition ,
and a stable Markov control policy 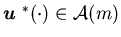 such that
such that 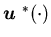 is optimal, i.e., it minimizes the cost defined by (4.1)
over all ,
and furthermore,
is optimal, i.e., it minimizes the cost defined by (4.1)
over all ,
and furthermore,
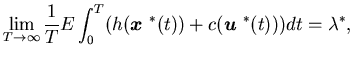
|
|
|
(4.3) |
where 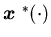 is the surplus process corresponding to
with .
Moreover, for any other (stable) control
is the surplus process corresponding to
with .
Moreover, for any other (stable) control 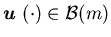 ,
,
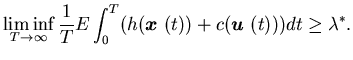
|
|
|
(4.4) |
Since we use the vanishing discount approach to treat our problem, we provide
the required results for the discounted problem. First we introduce a corresponding
control problem with the cost discounted at a rate 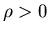 .
For ,
we define the expected discounted cost as
.
For ,
we define the expected discounted cost as
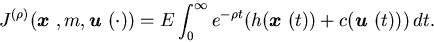
The value function of the discounted problem is defined as
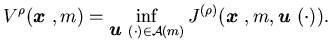
|
|
|
(4.5) |
In order to study the long-run average cost control problem using the vanishing
discount approach, we must first obtain some estimates for the value
function 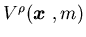 .
To do this, we give the following auxiliary lemma. Its proof is given in
Sethi,
Suo, Taksar and Zhang (1997).
.
To do this, we give the following auxiliary lemma. Its proof is given in
Sethi,
Suo, Taksar and Zhang (1997).
Lemma 4.1 For any ,
, ,
there
exist a constantC43 and a control policy
,
there
exist a constantC43 and a control policy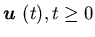 ,
such
that for
,
such
that for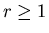 ,
,
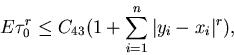 where
where
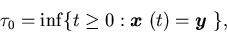 and
and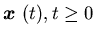 ,
is
the surplus process corresponding to the control policy
,
is
the surplus process corresponding to the control policy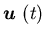 and
initial condition.
and
initial condition.
This lemma leads to the following result proved in
Sethi,
Suo, Taksar and Zhang (1997).
Theorem 4.1 For any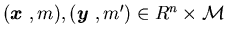 ,
there
exist a constant C44 and a control policysuch
that for,
,
there
exist a constant C44 and a control policysuch
that for,
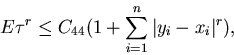 where
where
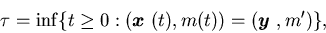 andis
the surplus process corresponding to the control policy and
initial condition.
andis
the surplus process corresponding to the control policy and
initial condition.
With Theorem 4.1 in hand, Sethi,
Suo, Taksar and Zhang (1997) prove the following theorem.
Theorem 4.2 (i) There exists
a constant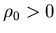 such
that
such
that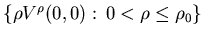 is
bounded.
is
bounded.
(ii) The function
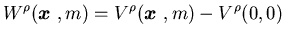 |
|
|
(4.6) |
is convex in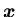 .
It
is locally uniformly bounded, i.e., there exists a constant C
45>0 such that
.
It
is locally uniformly bounded, i.e., there exists a constant C
45>0 such that
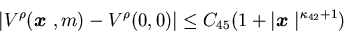
for all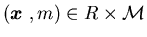 ,
,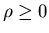 .
.
(iii)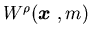 is
locally uniformly Lipschitz continuous in,
with
respect to,
i.e.,
for any X>0, there exists a constantC46>0,
independent
of
is
locally uniformly Lipschitz continuous in,
with
respect to,
i.e.,
for any X>0, there exists a constantC46>0,
independent
of 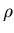 ,
such
that
,
such
that
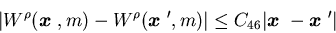
for all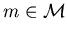 and
all
and
all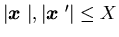 .
.
The HJB equation associated with the long-run average cost optimal control
problem as formulated above takes the following form
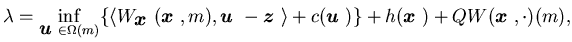
|
|
|
(4.7) |
where 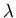 is a constant,
is a constant, 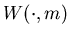 is a real-valued function, known as the potential function or the relative
value function, defined on
is a real-valued function, known as the potential function or the relative
value function, defined on 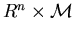 ,
,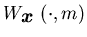 is the partial derivative of the relative value function
with respect to the state variable ,
and
is the partial derivative of the relative value function
with respect to the state variable ,
and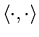 denotes the inner product Without requiring that
is C1, it is convenient to write the HJBDD for our problem.
The corresponding HJBDD equation can be written as
denotes the inner product Without requiring that
is C1, it is convenient to write the HJBDD for our problem.
The corresponding HJBDD equation can be written as
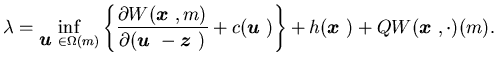
|
|
|
(4.8) |
Let 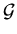 denote the family of real-valued functions
denote the family of real-valued functions 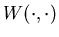 defined on
defined on 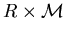 such that
such that
-
(i)
-
is convex;
-
(ii)
-
has polynomial growth, i.e., there are constants
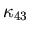 and C47>0 such that
and C47>0 such that
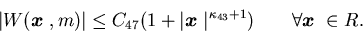
A solution to the HJB or HJBDD equation is a pair 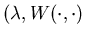 with
a constant and
with
a constant and 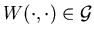 .
The function
is called the potential function for the control problem, if
is the minimum long-run average cost. From Theorem 4.2
follows the next result.
.
The function
is called the potential function for the control problem, if
is the minimum long-run average cost. From Theorem 4.2
follows the next result.
Theorem 4.3 For,
the
following limits exist:
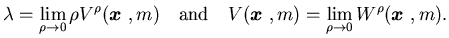
|
|
|
(4.9) |
Furthermore, 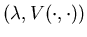 is
a viscosity solution to the HJB equation (4.7).
is
a viscosity solution to the HJB equation (4.7).
Using results from convex analysis, Sethi,
Suo, Taksar and Zhang (1997) prove the following theorem.
Theorem 4.4defined
in Theorem 4.3 is a solution to the HJBDD equation (4.8).
Remark 4.1 When there is no
cost of production, i.e., 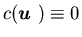 ,
Veatch and Caramanis (1997) introduce the following differential cost function
,
Veatch and Caramanis (1997) introduce the following differential cost function
![\begin{eqnarray*}\hat W({\mbox{\boldmath$x$ }},m)=\lim_{T \rightarrow \infty} ......^T _0h({\mbox{\boldmath$x$ }}^*(t))dt - T\lambda ^* \right ],\end{eqnarray*}](img592.gif) where m=m(0),
is the optimal value, and
where m=m(0),
is the optimal value, and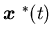 is the surplus process corresponding to the optimal production process
with
is the surplus process corresponding to the optimal production process
with 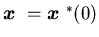 .
The differential cost function is used in the algorithms to compute a reasonable
control policy using infinitesimal perturbation analysis or direct computation
of average cost; see
Caramanis and Liberopoulos
(1992), and Liberopoulos and Caramanis (1995).
They prove that the differential cost function
.
The differential cost function is used in the algorithms to compute a reasonable
control policy using infinitesimal perturbation analysis or direct computation
of average cost; see
Caramanis and Liberopoulos
(1992), and Liberopoulos and Caramanis (1995).
They prove that the differential cost function 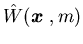 is convex and differentiable in .
If n=1,
h(x1)=|x1| and
is convex and differentiable in .
If n=1,
h(x1)=|x1| and  ,
we know from Bielecki and Kumar (1988) that
,
we know from Bielecki and Kumar (1988) that
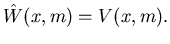
|
|
|
(4.10) |
This means that the differential cost function is the same as the potential
function given by (4.9). However so far,
(4.10) has not been established in general.
Now we state the following verification theorem proved by Sethi,
Suo, Taksar and Yan (1998).
Theorem 4.5 Let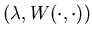 be
a solution to the HJBDD equation (4.8).
Then
the following holds.
be
a solution to the HJBDD equation (4.8).
Then
the following holds.
-
(i)
-
If there is a control such
that
| |
|
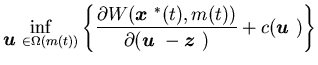
|
|
| |
|
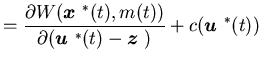
|
(4.11) |
for a.e.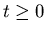 with
probability one, whereis
the surplus process corresponding to the control ,
and
with
probability one, whereis
the surplus process corresponding to the control ,
and
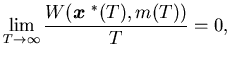
|
|
|
(4.12) |
then
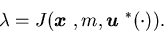
-
(ii)
-
For any ,
we
have
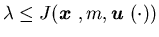 ,
i.e.,
,
i.e.,
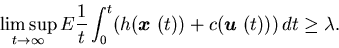
-
(iii)
-
Furthermore, for any (stable) control policy ,
we
have
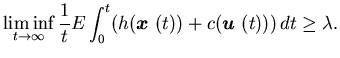
|
|
|
(4.13) |
In the remainder of this section, let us consider the single product case,
i.e., n=1. For this case, Sethi, Suo,
Taksar and Zhang (1997) prove the following result.
Theorem 4.6 ForandV(x,m)
given
in (4.9), we have
-
(i)
-
V(x,m) is continuously differentiable in x.
-
(ii)
-
is
a classical solution to the HJB equation (4.7).
Let us define a control policy 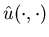 via the potential function
via the potential function 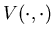 as follows:
as follows:
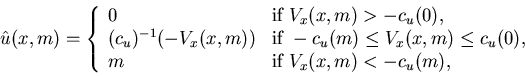 |
(4.14) |
if the function
is strictly convex, or
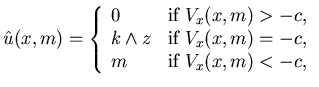
|
|
|
(4.15) |
if c(u)=cu. Therefore, the control policy
satisfies (i) of Theorem 4.5.
From the convexity of the potential function 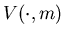 ,
there are
,
there are 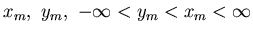 such that
such that
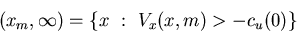
and
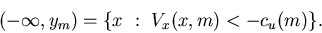
The control policy
can be written as
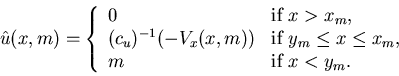 Then we have the following result.
Then we have the following result.
Theorem 4.7 The control
policydefined
in (4.14) and (4.15),
as
the case may be, is optimal.
Proof. By Theorem 4.5, we need
only to show that
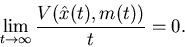
But this is implied by Theorem 4.6
and the fact that
is a stable control.  Remark
4.2 When c(u) =0, i.e., there is no production
cost in the model, the optimal control policy can be chosen to be the so-called
hedging
point policy, which has the following form: there are real numbers xk,
k=1,...,m,
such that
Remark
4.2 When c(u) =0, i.e., there is no production
cost in the model, the optimal control policy can be chosen to be the so-called
hedging
point policy, which has the following form: there are real numbers xk,
k=1,...,m,
such that
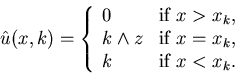 In particular, if h(x)
=c1x++c2x-
with
In particular, if h(x)
=c1x++c2x-
with 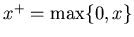 and
and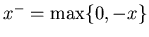 ,
we obtain the special case of Bielecki and Kumar (1988). This will be reviewed
next.
,
we obtain the special case of Bielecki and Kumar (1988). This will be reviewed
next.
The Bielecki-Kumar Case: Bielecki and
Kumar (1988) treated the special case in which h(x)=c1x++c2x-,
c(u)=0,
and the production capacity
is a two-state birth-death Markov process. Thus, the binary variable
takes the value one when the machine is up and zero when the machine is
down. Let 1/q1 and 1/q0 represent the
mean time between failures and the mean repair time, respectively. Bielecki
and Kumar obtain the following explicit solution:
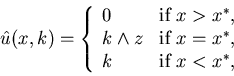 where
where
![\begin{eqnarray*}\hat x^*=\left \{\begin{array}{ll}0 &\mbox{if} \ \frac{q_......q_0+q_1)}\right]& \mbox{otherwise}.\\\end{array}\right.\end{eqnarray*}](img620.gif)
Remark 4.3 When the system equation
is governed by the stochastic differential equation
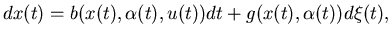
|
|
|
(4.16) |
where 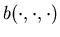 ,
,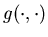 are suitable function and
are suitable function and 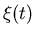 is a standard Brownian motion, Ghosh, Arapostathis,
Marcus (1993), Ghosh, Arapostathis, and
Marcus (1997) and Basak, Bisi and Ghosh (1997)
have studied the corresponding HJB equation and established the existence
of their solutions and the existence of an optimal control under certain
conditions. In particular, Basak, Bisi and Ghosh
(1997) allow the matrix
to be of any rank between 1 and n.
is a standard Brownian motion, Ghosh, Arapostathis,
Marcus (1993), Ghosh, Arapostathis, and
Marcus (1997) and Basak, Bisi and Ghosh (1997)
have studied the corresponding HJB equation and established the existence
of their solutions and the existence of an optimal control under certain
conditions. In particular, Basak, Bisi and Ghosh
(1997) allow the matrix
to be of any rank between 1 and n.
Remark 4.4 For n=2 and 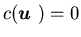 ,
Srivastsan
and Dallery (1998) limit their focus to only the class of hedging point
policies and attempt to partially characterize an optimal solution within
this class.
,
Srivastsan
and Dallery (1998) limit their focus to only the class of hedging point
policies and attempt to partially characterize an optimal solution within
this class.
Remark 4.5 Abbad,
Bielecki, and Filar (1992) and Filar, Haurie,
Moresino, and Vial (1999) consider the perturbed stochastic hybrid
system whose continuous part is described by the following stochastic differential
equation
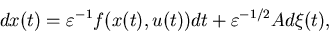 where
where 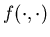 is continuous in both arguments,
A is an n x n matrix,
and
is a Brownian motion. The perturbation parameter
is continuous in both arguments,
A is an n x n matrix,
and
is a Brownian motion. The perturbation parameter 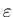 is assumed to be small. They prove that when
tends to zero, the optimal solution of the perturbed hybrid system can
be approximated by a structured linear program.
is assumed to be small. They prove that when
tends to zero, the optimal solution of the perturbed hybrid system can
be approximated by a structured linear program.
Next:4.2
Optimal control of dynamicUp:4.
Optimal Control with thePrevious:4.
Optimal Control with the